Afgelopen zaterdag viel in de Volkskrant te lezen dat Openbare Basisschool Overvecht in Utrecht het predicaat ‘excellent’ heeft gekregen van Staatssecretaris Sander Dekker. Dat is opvallend te noemen, aangezien de school in een aandachtswijk ligt en daardoor veel kinderen uit lagere sociaal-economische milieus opleidt. De gemiddelde CITO-score ligt de afgelopen jaren met 532 onder het landelijk gemiddelde.
Nu weet iedereen dat het onvoldoende is om alleen naar de CITO-scores kijken om de kwaliteit van deze basisschool te meten, want een score van 532 is hoger dan verwacht mag worden op basis van de sociaal-economische samenstelling van de leerlingen op de school. Jaap Dronkers heeft daarom een ranglijst van basisscholen gemaakt, waarvoor hij de CITO-scores heeft gecorrigeerd voor de sociaal-economische samenstelling van de leerlingen en de buurt. Deze lijst is door het RTL Nieuws in september gepubliceerd en heeft sindsdien de nodige kritiek te verduren gekregen. Zo heeft Thijs Bol op dit blog op verschillende methodologische tekortkomingen gewezen (zie hier voor een respons van Dronkers op Bol). In dit stuk pas ik het model van Dronkers op een aantal punten aan, wat de verklaringskracht van het model en de uiteindelijke berekening van de toegevoegde waarde van een school ten goede komt.
Sociaal-economische compositie
Eén van de belangrijkste kritiekpunten van bijvoorbeeld Bol is dat zo’n gecorrigeerde lijst pas gepubliceerd mag worden als er goede data van de sociaal-economische compositie van de scholen zijn. Het lijkt er inderdaad op dat daar beter voor gecorrigeerd had kunnen worden. Mijn grootste aanpassing aan Dronkers’ model is dan ook dat de sociaal-economische compositie op een andere manier gemeten wordt.
Verschillen tussen basisscholen in de gemiddelde CITO-scores hebben niet alleen te maken hebben met de kwaliteit van de school, maar ook (en vooral) met de sociaal-economische samenstelling van de leerlingen. Het aantal openbare gegevens van de scholen en de leerlingen is echter beperkt, waardoor onderzoekers enigszins moeten schipperen in hun analyses. Idealiter zou je van alle leerlingen de sociaal-economische kenmerken in de analyses betrekken. De bekende sociaal-economische kenmerken van de leerlingen beperken zich echter tot het land van herkomst en de zogenaamde ‘gewichtenleerlingen’ (leerlingen waarvoor een school extra bekostiging kan krijgen op basis van de lage opleiding van de ouders). Dit is echter onvoldoende om voor de verschillen tussen de kinderen te corrigeren.
Daarom heeft Dronkers voor zijn ranglijst de sociaal-economische status van de buurt toegevoegd aan de analyses vanuit de gedachte dat de leerlingenpopulatie een redelijke afspiegeling is van de buurtpopulatie. Hiervoor heeft Dronkers gebruik gemaakt van de dimensie (sociaal-economische) bevolkingssamenstelling van de Leefbaarometer. Het probleem hiermee is dat deze dimensie weliswaar is samengesteld uit verschillende sociaal-economische indicatoren, maar dat deze dimensie nooit bedoeld is geweest voor dit soort analyses. De achterliggende indicatoren zijn geoperationaliseerd ten einde zo goed mogelijk de leefbaarheid te voorspellen en niet om de sociaal-economische situatie van de ouders in de buurt weer te geven. De coëfficiënten en lineariteit geven de samenhang met het leefbaarheidsoordeel weer, niet met de sociaal-economische status van de buurt. Daarnaast wordt de dimensie dusdanig weergegeven dat er weinig variatie binnen hele sterke en hele zwakke buurten is. Ten slotte zorgt het toevoegen van deze samengestelde variabele voor een ‘dubbeltelling’ in de analyses. Het aandeel niet-westerse allochtonen heeft een relatief groot aandeel in de dimensiescore van de Leefbaarometer. Maar de afkomst van de leerlingen is al rechtstreeks bekend en hoeft dus niet via een omweg ingeschat te worden door te kijken naar de buurt.
De belangrijkste aanpassing van het model is dat gebruik gemaakt wordt van individuele indicatoren met betrekking tot de sociaal-economische status, zoals opleidingsniveau, inkomen, werkloosheid en huishoudenssituatie (eenoudergezinnen). Dit zorgt er voor dat de coëfficiënten en de lineariteit van de individuele indicatoren beter weergeven hoe ze de CITO-scores beïnvloeden dan de samengestelde dimensie.
Daarnaast zijn er nog een aantal andere aanpassingen op het model van Dronkers doorgevoerd. Zo zijn alleen basisscholen met een CITO-toets meegenomen. Dronkers heeft ook scholen met een andere eindtoets meegenomen door het gemiddelde en de spreiding van de toetsen van die scholen gelijk te veronderstellen aan de CITO-scores. Lex Borghans heeft al aangegeven dat dat niet heel waarschijnlijk is. Het niet opnemen zorgt voor een toename van vijf procent van de verklaarde variantie. Deze verbetering van het model is een aanwijzing dat scholen met verschillende soorten eindtoetsen niet zonder meer vergelijkbaar zijn. Alvorens scholen met verschillende toetsen te vergelijken zou eerst een methode ontwikkeld moeten worden om de toetsscores langs dezelfde meetlat te leggen. Ten slotte is het deelnamepercentage aan de CITO-toets en de ligging van een school in een impulsgebied (waarvoor het extra financiering krijgt) in het model meegenomen (en niet vooraf voor gecorrigeerd).
Hogere verklaringskracht
In tabel 1 zijn de uitkomsten van het aangepaste model te zien. Dit aangepaste model voorspelt de gemiddelde CITO-scores voor 55 procent. De aanpassingen hebben gezorgd voor een aanzienlijke verbetering ten opzichte van het model van Dronkers, dat een verklaarde variantie van 39 procent heeft. Niet-significante verbanden (zoals bijvoorbeeld het aandeel Antilliaanse leerlingen) zijn uit het model verwijderd. Het is immers onterecht om scholen af te rekenen (of te belonen) op basis van verbanden die statistisch niet hard te maken zijn. Deze uitkomst laat zien dat met een aantal methodologische aanpassingen bezwaren met betrekking tot het publiceren van een lijst met schoolprestaties in ieder geval deels weggenomen kunnen worden.
{kind=link}
De kwadratentermen en interacties maken de uitkomsten overigens wat lastig te interpreteren. De aandelen minimum en lage inkomens hebben een (berg)parabolische samenhang met de CITO-scores en hangen in het relevante domein negatief samen met de CITO-scores. De aandelen bovenmodale inkomens en hoger opgeleiden hangen in het relevante domein positief samen met de CITO-scores. De interacties tussen de aandelen Surinamers, Turken, Marokkanen en overige niet-westerlingen en de aandelen laag opgeleiden of minimum inkomens moeten vooral gezien worden als kleine correctie ten opzichte van de negatieve samenhang tussen de aandelen Surinamers, Turken, Marokkanen en overige niet-westerlingen en de CITO-scores.
Verschillen tussen modellen
Ondanks de verbetering is de correlatie tussen de uitkomsten van beide modellen hoog, namelijk 91 procent. Dat wijst erop dat het model redelijk robuust is voor aanpassingen en dat er enig vertrouwen in de uitkomsten kan zijn. Om een globaal inzicht te krijgen in de prestaties van de scholen, maakt de modelaanpassing weinig verschil.
Weliswaar zijn er duidelijke overeenkomsten in de modeluitkomsten, maar voor veel individuele scholen maken de modelaanpassingen wel degelijk verschil, met name als je letterlijk een ranglijst van scholen gaat publiceren zoals Dronkers en RTL Nieuws hebben gedaan. Deze modellen zijn niet geschikt om een rangorde in scholen aan te brengen, omdat hiervoor de onzekerheden te groot en de verschillen tussen de scholen te klein zijn. Een kleine modelaanpassing kan al voor een verschuiving van vele plaatsen zorgen voor een individuele school, zonder dat er iets wezenlijks veranderd is in de modellen.
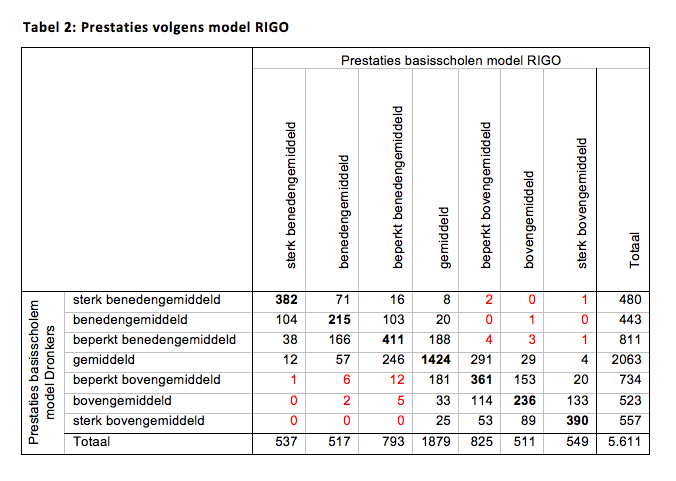
Met behulp van deze modellen is het wel mogelijk om scholen onder te verdelen in groepen die boven- of benedengemiddeld presteren. Tabel 2 laat een kruising zien tussen de groepen volgens het model van Dronkers en de groepen volgens mijn model. Er zijn nauwelijks scholen die in het ene model benedengemiddeld scoren en het andere bovengemiddeld. In totaal gaat het om slechts 38 van de 5.600 scholen waarvoor de inschatting de andere kant op valt (de rode gekleurde vakjes in de tabel). Er worden dus nauwelijks scholen negatief beoordeeld die in het andere model positief beoordeeld zijn (of vice versa). Vanuit dat oogpunt vallen de verschillen voor de scholen dus wel mee. Maar tegelijkertijd blijkt dat liefst veertig procent van de scholen in een andere categorie terecht komt in dit aangepast model (bijvoorbeeld van sterk bovengemiddeld in plaats van beperkt bovengemiddeld).
Conclusie
Het meten van de kwaliteit van scholen is verre van eenvoudig. Dronkers heeft terecht geprobeerd de toetsscores te corrigeren voor de sociaal-economische compositie van de scholen. Dit stuk laat zien dat het model van Dronkers met een aantal aanpassingen verbeterd kan worden en zo bezwaren met betrekking tot de publicatie ervan (gedeeltelijk) kan wegnemen. De verklaringskracht van mijn model is duidelijk hoger, voornamelijk omdat beter is gecorrigeerd voor de sociaal-economische compositie van de scholen.
Voor individuele basisscholen maakt de modelaanpassing ook uit. Op zich zijn er weinig scholen die in het ene model als goed en in het andere als slecht worden beoordeeld. Maar het is wel zo dat liefst veertig procent van de basisscholen in een andere categorie terecht komt in dit aangepaste model. De ‘excellente’ Openbare basisschool Overvecht presteert bijvoorbeeld volgens dit aangepaste model bijvoorbeeld ‘sterk bovengemiddeld’, wat beter overeenkomt met de inschatting van de Staatssecretaris dan de ‘bovengemiddelde’ kwaliteit volgens het model van Dronkers.
Basisscholen op de kaart
Op de onderstaande kaart is te zien hoe de scholen presteren volgens dit aangepaste model.
Fantastisch stuk! Het doet precies wat we, volgens mij, moeten doen: (1) werken met de beste data en (2) geen precieze ranglijsten publiceren. Vraag blijft natuurlijk wel hoe groot de meetfout in jouw model is (alle data is beperkt; en ook dit is geen schooldata), en wat het effect daarvan is op de uiteindelijke categorisering. Ik ben benieuwd naar Jaap’s reactie.
Prima verhaal. Het laat weer eens zien dat dit soort onderzoeken weliswaar interessante gegevens opleveren voor wetenschappelijk onderzoek, maar ten enenmale ongeschikt zijn om ranglijsten samen te stellen, laat staan om beleid op te baseren. In mijn bijdrage aan het boek ‘Het Alternatief’ (red. René Kneyber en Jelmer Evers) laat ik zien dat toegevoegde waarde een onbetrouwbare maatstaf is voor onderwijskwaliteit, o.a. omdat die afhangt van de methode om toegevoegde waarde te berekenen. De britse onderzoeker Dylan Wiliam schreef in 2012 een essay (Are there “Good” schools and “Bad” schools?) in het boek ‘Bad Education – Debunking Myths in Education’ (red. Philip Adey en Justin Dillon). Daarin concludeert hij dat, als je alle factoren meerekent waarop scholen geen invloed hebben (met name sociaal-economische status van de gezinnen) er nauwelijks verschillen zijn tussen scholen. Wiliam concludeert: “There are no good or bad schools”.
Ranglijstjes als die van Dronkers zijn onzin en kunnen voor scholen heel slecht uitpakken.
Wetenschappers, zoals de auteurs op deze blog, zouden er goed aan doen beleidsmakers ervan te overtuigen dat dit een heilloze – en potentieel schadelijke – weg is. Zie dit artikel op .
Ik ben het deels eens met uw respons over de manier waarop ranglijsten (niet alleen van scholen, maar ook van universiteiten, ziekenhuizen, etc) worden gebruikt, maar de zin “there are no good or bad schools” gaat toch een aantal stappen te ver? Je kunt op equivalente groepen leerlingen toch totaal verschillende curricula, docenten, voorzieningen etc. loslaten?
Zeker. Misschien is Wiliams opmerking een beetje ongenuanceerd. Maar zijn punt is dat de verschillen in toets- en examenresultaten, ‘opbrengst’, afhangen van factoren die niets met onderwijskwaliteit van doen hebben.
Een interessant gedachtenexperiment dat dit illustreert vind je hier http://vamboozled.com/?p=706
De verschillen tussen scholen zijn om een andere reden niet boeiend: de verschillen binnen een school zijn veel groter. Op goede scholen worden de meeste slechte lessen gegeven, omdat er nu eenmaal meer goede scholen zijn.
N.B. het artikel op het Blogcollectief, waar ik naar verwijs, staat hier http://onderzoekonderwijs.net/2013/11/14/toegevoegde-waarde-meten-is-nog-lang-niet-van-de-baan/
Interessant werk, die op een andere manier laat zien wat Thijs Bol al eerder aantoonde: verschillen in aannames maken grote verschillen in lokale ranglijsten.
Wat ik zie als de twee grootste methodologische problemen bij deze aanpak zijn echter niet opgelost.
1. De sociaal-economische compositie van de school wordt afgeleid via de postcodes van de leerlingen, en dat gaat niet. In NL is schoolsegregatie (veel) groter dan wijksegregatie. Het is geen toeval welke leerlingen uit dezelfde postcode naar verschillende scholen gaan.
2. Scholen verschillen in de aanname van zorgleerlingen. De correctiemethodiek is m.i. in het nadeel van scholen die relatief veel zorgleerlingen opnemen. Net niet wat je zou willen.
En dit nog los van de wenselijkheid om überhaupt ranglijsten te produceren natuurlijk.
Arnold Jonk stelt hierboven dat schoolsegregatie veel groter is dan wijksegregatie, en dat daarom de postcode van de leerlingen onbruikbaar is als indicator voor sociaal-economische samenstelling van basisscholen. Ik toets zijn stelling met behulp van het percentage leerlingen met een leerlinggewicht (=laaggeschoolde ouders) per basisschool en per postcode (een wijk bevat meestal meerdere postcodes). Het belang van deze analyse, waarbij ik gebruik maak van DUO data, is dat de segregatie van postcodes en scholen uitsluitend gebaseerd is op dezelfde ouders van de betrokken basisschoolleerlingen en niet op alle bewoners in postcodes. Omdat de aanwezigheid van gezinnen met schoolgaande kinderen nogal kan verschillen per postcode (bijvoorbeeld als gevolg van vergrijzing of gentrificatie van buurten) voorkomt deze beperking tot dezelfde ouders met basisschoolleerlingen vertekening in de mate van postcode segregatie. In tabel 1 staan de uitkomsten voor de basisscholen en de postcodes.
Per postcode gebied zijn er dus ongeveer 2 basisscholen (5855/2889). Op basisscholen ligt het gemiddeld percentage leerlingen met laaggeschoolde ouders 2% hoger dan per postcode. De standaard deviatie van het percentage basisschoolleerlingen met laag geschoolde ouders is iets groter voor scholen dan voor postcodes. Het zelfde geldt voor de scheefheid van de verdeling: iets groter voor scholen dan voor postcodes. Dat betekent dat er iets meer scholen met zeer hoge percentages laaggeschoolde ouders voorkomen dan postcodes met zeer hoge percentages laaggeschoolde ouders. De maxima weerspiegelen dit ook: er is een basisschool waarvan 100% van de ouders laaggeschoold is, terwijl dat percentage voor de postcode 77% is. Maar er zijn zowel postcodes als scholen met 0% laaggeschoolde ouders.
Het is op grond van deze kleine verschillen tussen de percentages laag geschoolde ouders per school en per postcode onjuist te beweren dat postcode- en schoolsegregatie zo sterk uiteenlopen dat de postcode van leerlingen onbruikbaar zou zijn voor de vaststelling van de sociaal-economische populatie van basisscholen.
De onderwijsinspectie vindt dat blijkbaar zelf ook. Zij gebruikt het percentage leerlingen uit armoedeprobleemcumulatie gebieden op de kwaliteitskaarten voor het voortgezet onderwijs en ook op Vensters van Verantwoording van de VO-raad wordt dit percentage zonder omslag gebruikt.
Het is betreurenswaardig dat de hoofdinspecteur primair onderwijs en expertisecentra de feiten op zijn terrein zo slecht kent en niet weet wat er elders bij de onderwijsinspectie gebeurt.
Twee punten:
– Die postcode analyse is zo zinvol niet, om veel verschillende redenen. Zie het werk van onder meer Lex Herweijer naar de verschillen tussen wijk- en schoolsegregatie. In de grote steden is dat heel fors. Ranglijsten werken lokaal. Je moet dus lokaal kijken.
– De opmerking over armoedeprobleemcumulatiegebieden begrijp ik niet. Dit gaat over basisscholen. Bij basisscholen maken wij daar geen gebruik van. Dat weet ik als hoofdinspecteur natuurlijk prima. In het voortgezet onderwijs spelen echt andere mechanismen met andere financiering. Het is niet zo zinvol ranglijsten te maken zonder begrip voor de onderwijssector, de financiering en de mechanismen in die sector.
Het gebruik door René Schulenburg van een nauwkeuriger meting van de sociaal-economische compositie van scholen (afzonderlijke indicatoren voor inkomen en opleidingsniveau, werklozen en eenoudergezinnen in plaats van de optelsom deze indicatoren van de Leefbaarometer) is een stap vooruit. Ik had in mijn bijdrage aan de RTL publicatie over de CITO-scores ook veel liever deze afzonderlijke dimensies gebruikt. In mijn toelichting bij deze publicatie zeg ik daarover in voetnoot 11: “Deze koppeling van bevolkingsdimensie kenmerken per wijk en postcodes van leerlingen is echter niet de beste mogelijkheid. Beter zou zijn de beroepen en opleidingsniveaus van de ouders van de leerlingen te gebruiken om de sociale compositie van scholen vast te stellen. Deze informatie is wel beschikbaar bij CBS en/of DUO, maar is buiten het bereik van zelfstandige onderzoekers en beschikbaarstelling is aan onwerkbare restricties onderworpen.“
René Schulenburg doet het in zijn analyse voorkomen alsof deze indicatoren wel beschikbaar zijn. Maar toen ik hem vroeg mij deze indicatoren te verschaffen, zodat ik de onvolkomenheden in zijn analyse (zie hier onder) zou kunnen corrigeren, antwoordde hij: “Ik heb het voordeel dat wij (= het bedrijf waar hij werkt) de Leefbaarometer maken (en alle indicatoren waaruit die is opgebouwd). Een deel van die data komt van marketingbureaus als het WDM/Cendris/Experian (wdm in dit geval). En die zijn erg duur zoals u al opmerkte. BZK koopt dat soort data in en wij bewerken ze. Maar we mogen die niet openbaar maken of verspreiden, dus daar heeft u niets gemist.”
Niemand op de universiteit (want geen vakgroep heeft genoeg geld en ik dus ook niet) kan dus zijn bijdrage narekenen. Daardoor is de bijdrage van René Schulenburg geen wetenschappelijke product meer, want repliceerbaarheid en controleerbaarheid is een wezenskenmerk van de wetenschap. Dit narekenen is nogal belangrijk want René Schulenburg claimt 17% meer verklaarde variantie te vinden. Die hogere verklaarde variatie kan niet alleen komen door alleen de scholen met een echte cito-toets te gebruiken. Volgens mij verhoogt het niet-gebruiken van basisscholen zonder cito-toets de verklaarde variantie maar met 2%. Het lijkt mij sterk dat de overige 15% extra verklaarde variantie komt door zijn gebruik van de afzonderlijke indicatoren in plaats van mijn gebruik van de combinatie van die indicatoren. Zijn extra variabelen, zijn kwadratische termen of zijn interactie-termen kunnen nauwelijks geleid hebben tot zoveel meer verklaarde variantie.
Dit voorval laat nog eens zien dat de macht van de bezitters van data en de financiers van onderzoek niet alleen speelt in de bèta wetenschappen (farmaceutische industrie), maar evenzeer in de sociale wetenschappen. Ik zal in de toekomst blijven pogen betere indicatoren boven tafel te krijgen, maar het past René Schulenburg niet mij te verwijten dat ik iets niet gebruik waaraan ik niet kan komen en dat hij niet mag geven.
In mijn eerdere antwoord op de kritiek van Thijs Bol heb ik al gezegd dat analyse modellen beoordeeld moeten worden of een bepaald model het bedoelde concept het best meet, niet of er geen andere modellen mogelijk zouden zijn. In dit geval is het de bedoeling dat toegevoegde waarde van een school de prestaties van leerlingen meet, waarbij uitsluitend gecorrigeerd wordt voor de kenmerken van de leerlingen. Schoolkenmerken of variabelen die indirect schoolkenmerken horen dus niet in een model thuis dat toegevoegde waarde wilt meten, ook al komt er wat anders uit of al is de verklaarde variantie hoger. Analyses horen geleid te worden door inhoudelijke overwegingen, niet door wiskundige of statistische.
Vanuit dit perspectief is opname van de variabele “Ligging in impulsgebied” door René Schulenburg in zijn vergelijking simpelweg fout. Deze variabele meet of de school ligt in een Vogelaarwijk ligt en dus extra financiële steun krijgt. Door deze variabele in zijn vergelijking op te nemen te samen met de sociaal-economische samenstelling van de school op grond van de postcodes van de leerlingen krijgt deze variabele nog nadrukkelijker het karakter van een schoolkenmerk. En die hoort niet thuis in een regressievergelijking is de bedoeling heeft toegevoegde waarde te meten.
Het zelfde geldt voor zijn kwadratische termen in zijn vergelijking. In de meeste gevallen lijken die eerder school processen te meten dan specifieke kenmerken van de leerling populatie. In voetnoot 21 van mijn toelichting ga ik daarop in naar aanleiding van de analyse van Thijs Bol. René Schulenburg geeft ook toe dat zijn kwadratische termen moeilijk te interpreteren zijn. Mag je moeilijk te interpreteren termen wel opnemen in een regressievergelijking? Volgens mij luidt het goede antwoord nee. In mijn analyse heb ik een keer wel een kwadratische term opgenomen in de vergelijking, namelijk het kwadraat van de sociaal-economische compositie. Die opname verantwoord ik dan ook inhoudelijk in voetnoot 20 van mijn toelichting: “Deze kwadratische variabele is opgenomen omdat zo beter rekening gehouden wordt met scholen die veel leerlingen uit wijken met de hoogste status hebben.”
De claim van René Schulenburg dat zijn model een grotere verklaringskracht zegt daarom niets. De vraag is altijd verklaringskracht waarvoor? Het toevoegen van nog meer schoolkenmerken (denominatie, % goed opgeleide leerkrachten, etc.) zal de verklaringskracht zonder twijfel nog verder vergroten, maar het resultaat meet nog minder het bedoelde concept, namelijk toegevoegde waarde.
De hogere verklaarde variantie van maximaal 2% is geen bewijs dat mijn omzetting van de andere eindtoetsscores fout is. Het kan ook komen doordat scholen die geen citotoets afnemen gemiddeld lagere of meer onvoorspelbare resultaten hebben (zie mijn lezing CITO eindtoetsen op twee niveaus? Forum expertmeeting 3 December 2012). In het licht van de resultaten van het AMCIS paper van T. Bol, J. Witschge, H.G. van de Werfhorst & J. Dronkers. Curricular Tracking and Central Examinations: Counterbalancing the Impact of Social Background on Student Achievement in 36 Countries (binnenkort in Social Forces) is lagere of slechter voorspelbare eindtoetsscores bij die scholen die geen cito-toets gebruiken een veel aannemelijker verklaring. Overigens kan ik op de interactieve kaart van René Schulenburg tal van basisscholen niet terugvinden waarvan ik zeker weet dat zij de cito toets gebruiken.
Ook komt in zijn vergelijking een hoofdeffect (Antilliaanse leerlingen) niet voor, terwijl dat wel moet. Hoofdeffecten mogen niet uit een vergelijking worden weglaten ook al zijn ze niet significant, wanneer ze deel uitmaken van een significante interactie (in dit geval Antilliaanse leerlingen/minimum inkomens) die wel in de vergelijking is opgenomen. Als verbanden niet significant zijn (in die geval een hoofdeffect) dan wordt geen school benadeeld als hij toch in de vergelijking staat (in tegenstelling tot wat René Schulenburg zegt).
De afwijking tussen de resultaten van René Schulenburg en mij zelf kunnen dus erg goed komen door onvolkomenheden in zijn analyse en zijn onbekendheid van de onderwerpen toegevoegde waarde en schooleffectiviteit. Daarom drie literatuur aanwijzingen: het standaard werk J. Scheerens & R. Bosker, (1997). The Foundations of Educational Effectiveness. Kidlington/New York/Toyko: Pergamon; een boek met de Nederlandse discussie naar aanleiding van de publicatie van schoolresultaten in Trouw A. B. Dijkstra, S. Karsten, R. Veenstra & A. J. Visscher (red.) (2001) Het oog der natie: scholen op rapport. Standaarden voor de publicatie van schoolprestaties. Assen: Koninklijke van Gorcum; en een vaktijdschrift School Effectiveness and School Improvement.
De eerste zin in de reactie van Jaap Dronkers geeft eigenlijk precies weer hoe mij analyses gezien moeten worden: als een voorbeeld hoe het model van Dronkers verder geholpen kan worden. Ik pretendeer zeker niet het definitieve model te hebben gemaakt of wetenschap te bedrijven. Volgen mij kunnen er zowel qua data als conceptueel nog een aantal behoorlijke stappen gezet worden. Ik kan me dan ook best vinden in het commentaar dat er in mijn analyses wel wat verbeteringen mogelijk zijn. Tegelijkertijd vind ik ook dat Dronkers wel erg makkelijk aan al eerder gedane tips en reacties voorbij gaat.
Het is bijvoorbeeld wat ongelukkig van mij geweest om geen openbare data te gebruiken, waardoor mijn analyses niet nagerekend kunnen worden. Het ging mij echter niet zozeer om een nieuwe ranglijst te maken of het definitieve model te presteren, maar vooral te laten zien wat er gebeurt als andere data gebruikt wordt. Ik heb Dronkers afgelopen week over de mail ook al gewezen op de aanwezigheid van geschikte openbare data. Het CBS heeft op pc4-/buurtniveau openbare data beschikbaar als het gaat om opleiding, inkomen, werkloosheid, gezinssituatie etc.. Die zijn prima bruikbaar voor deze analyses (voor een deel heb ik daar gebruik van gemaakt en ik had er misschien wel beter volledig gebruik van kunnen maken). Er is dus veel meer mogelijk in het gebruik van nauwkeurige en specifieke data dan Dronkers in zijn reactie en zijn voetnoot doet voorkomen. De data die ik gebruikt heb, is slechts één van de mogelijkheden. En daar gaat Dronkers te makkelijk aan voorbij door alleen maar in te gaan op deze specifieke databron.
Conceptueel is er ook nog wel een stap te zetten. En dan met name hoe om te gaan met de (beperkt) beschikbare data. Daarmee moet geprobeerd worden een reconstructie te maken van de sociaaleconomische samenstelling van de leerlingen. Gewoon lineair en onbewerkt toevoegen van een aantal indicatoren is vermoedelijk geen voldoende proxy. Dat heeft Dronkers zelf ook geconstateerd getuige de kwadratenterm van de dimensie bevolkingssamenstelling die hij heeft gebruikt. Ik heb de kwadratentermen om precies dezelfde reden toegevoegd: proberen de sociaaleconomische compositie van de school te construeren uit omgevingskenmerken en om niet te ver af te wijken van Dronkers’ model. Het kan zijn dat kwadratentermen niet de goede oplossing is, juist daar is conceptueel nog wel een stap te maken. Maar aangezien Dronkers zelf ook gebruik maakt van een kwadratenterm van de omgevingskenmerken vind ik zijn kritiek enigszins curieus. Daarnaast betekent dat als de uitkomsten van kwadratentermen moeilijk te interpreteren zijn niet automatisch dat ze niet opgenomen moeten worden. Moeilijk betekent niet automatisch verkeerd. Moeilijk te interpreteren betekende in deze overigens dat een kwadratenterm met zich meebrengt dat het verband parabolisch is en dus zowel negatief of positief kan zijn, afhankelijk in welk deel van de parabool het relevante domein zich bevindt. Daarom heb ik dat toegelicht, zodat de lezer niet zelf allerlei mathematische afleidingen hoeft te maken om de richting van het verband te begrijpen.
Conceptueel moet er inderdaad goed nagedacht worden wat schoolgebonden processen zijn en wat niet. Als bijvoorbeeld een school extra geld krijgt omdat ze in een impulsgebied ligt (dat een ander niet krijgt), lijkt me dat geen schoolgebonden proces. Een school met exact dezelfde sociaaleconomische samenstelling die niet in een impulsgebied ligt is dan immers in het nadeel omdat het daarvoor geen extra financiering krijgt. Daarnaast zijn er tussen de impulsgebieden grote verschillen in sociaaleconomische samenstelling. Daarom lijkt het me dat je deze juist wél moet meenemen, in combinatie met andere sociaaleconomische kenmerken.
Een andere voorbeeld hiervan is Dronkers’ al eerder aangehaalde commentaar op de kwadratische termen. Volgens Dronkers leren scholen omgaan met veel achterstandsleerlingen en moeten die achterstandsleerlingen niet als kwadratische termen in het model worden gestopt, omdat je anders schoolgebonden processen weg corrigeert. Maar dat scholen met veel achterstandsleerlingen leren omgaan is misschien toch wel een aanwijzing dat die achterstanden niet lineair moeten worden toegevoegd. Is het een schoolgebonden proces als iedere school bijna automatisch leert van het aantal achterstandsleerlingen waar ze jaar-in-jaar-uit mee te maken hebben? Het gaat er volgens mij om of ze extra presteren bovenop die bijna automatische leercurve die bijna iedere school in zo’n situatie vermoedelijk zal doormaken. Dan mag ik volgens Dronkers wel niet bekend zijn met de literatuur, dat dit specifieke model conceptueel nog niet uitontwikkeld is, is me wel duidelijk.
Ten slotte de interactieterm en het niet opnemen van de niet-significante hoofdterm. Methodisch heeft Dronkers gelijk dat je dat eigenlijk niet moet doen. Je moet echter nadenken wat het opnemen ervan doet in je model en vooral met het gebruik van de uitkomsten ervan. In de meeste gevallen worden regressieanalyses gebruikt om samenhangen/verbanden tussen variabelen te laten zien. In dit geval wordt regressieanalyse echter gebruikt om van iedere school een score te berekenen. Je moet daarom nadenken hoe je voor zoveel mogelijk scholen een zo betrouwbare score kunt berekenen. Een niet-significante variabele betekent in dit geval dat er een (relatief) grote spreiding is. Een school die ver weg van de best passende lijn ligt (waarvan er veel zijn, gezien de niet-significantie) kan zo een waarde krijgen die zover afwijkt van wat reëel is, dat de voorspelde score van al die – op die niet-significante hoofdterm – afwijkende scholen niet betrouwbaar meer zijn. Het lijkt mij een groter probleem om significante interactie-effecten weg te laten dan om dat te doen met niet-significante hoofdeffecten. Het gevaar bij dit type analyses is juist dat een hoofdeffect (ten onrechte) significant is omdat geen rekening is gehouden met het interactie-effect. In dit geval zou je zonder interactie waarschijnlijk wel een hoofdeffect hebben (en dan onterecht de Antillianen over een kam scheren) omdat er waarschijnlijk meer Antillianen met lage inkomens dan met hoge inkomens zijn. Voor het totaal aan scholen zal het iets beter zijn de niet-significante hoofdterm op te nemen. Voor sommige individuele scholen zijn de scores dan niet bruikbaar. De vraag die dan voorligt is wat problematischer is. Ik denk in dit geval het tweede, maar sluit niet uit dat het beter kan.
Het is ten slotte jammer dat Dronkers de uitkomsten als onwaarschijnlijk afdoet. Want de cijfers zijn wel degelijk correct. De aanname dat de verbetering voor een groot deel komen door – volgens Dronkers – onvolkomenheden in de analyses klopt ook niet. Als ik zijn voorstellen volg kom ik nog altijd op een verklaarde variantie van 51 procent uit (in plaats van 55 in mijn model en 39 in dat van Dronkers). De discussie gaat dus over de vraag of die vier procent extra verklaarde variantie schoolgebonden prestaties zijn of niet.
Ook bij deze verbeterde methodiek zie je de waddeneilanden onderaan bungelen. Dit betekent, dat de correctie voor SES nog steeds te grof is (door specifiek omstandigheden passen de waddeneilanden niet in gangbare SES modellen). Bij welke verklaarde variantie is het ethisch verantwoord om een ranglijst of een kwalificatie “beneden gemiddeld” aan een school te plakken? 39%, 55%? De impact van een oordeel van een wetenschapper op het imago van een school kan groot zijn. Mijns inziens zijn modellen met een verklaarde variantie van 39 en 55 procent geen basis om een etiket op een school te plakken. Daar horen veel zwaardere eisen aan gesteld te worden. In die zin blijf ik het gedrag van met name Jaap Dronkers, die een rapportcijfer verbindt aan een school en dit vervolgens via een commercieel medium verkoopt gewoon onethisch vinden. Een geloofwaardige wetenschappelijke gemeenschap hoort hier tegen op te treden.
Ben het volkomen met je eens, Jan. Ik heb geen enkele moeite met het ontwikkelen van wetenschappelijke methoden om de kwaliteit van onderwijs te bepalen, mits wetenschappers verantwoordelijk omgaan met hun conclusies. In de natuurwetenschappen (mijn tak van sport) is het gebruikelijk om onzekerheidsmarges aan te geven. Aangenomen dat de methoden die hier besproken worden betrouwbaar zijn (en daarop valt veel af te dingen, zie ook de amerikaanse literatuur), dan zouden die marges wel eens een flinke overlap kunnen vertonen. Weer een reden om de scholenranglijstjes als onzin af te doen.
Ik schreef al eerder dat RTL, De Volkskrant en Dronkers aansprakelijk gesteld zouden moeten worden voor de schade die scholen van hun lijstjes ondervinden.
Als onderzoekers enige complexiteit niet uit de weg gaan, is het dan ook mogelijk te onderzoeken wat de invloed is van allerlei factoren en personen op de ontwikkeling van kinderen en hun leerprestaties? Zoals familie, kinderopvang, vijetijdsactiviteiten als sport, scouting, theater en muziek, jeugdwelzijn, jongerenwerk, mentoriimg, hulpverlening, werk, nachtrust en meer in het algemeen de ontwikkelingsgerichte kwaliteit van de tijdsbesteding van de jeugd? Bijv. ook tbv het wetenschappelijk beoordelen en begrijpen van Robert Putnams ‘Our Kids’?