
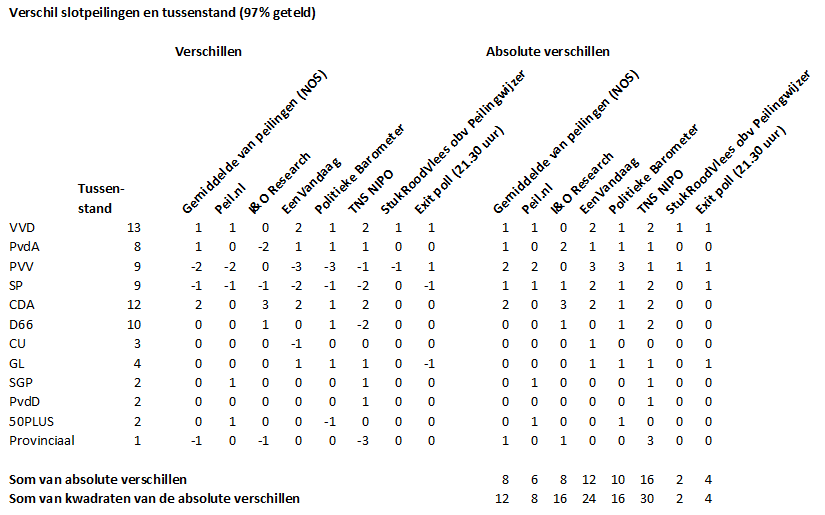
Hieronder een vergelijking tussen de einduitslag en de slotpeilingen van diverse bureaus alsook het gemiddelde dat ik voor de NOS berekende en de omrekening van de Peilingwijzer voor de Tweede Kamer die ik op deze site presenteerde. Over het algemeen is het beeld best gunstig. Maurice de Hond zat er, in zetels gemeten, van de vijf peilers het dichtste bij. De op deze site toegepaste methode werkte echter het allerbeste als men deze zou willen zien als een prognose voor de uitslag, zowel in zetels als in percentage uitgedrukt.
Peilers wijzen er altijd op dat verschillen tussen hun slotpeiling en de uitslag goed het resultaat kunnen zijn van late beslissers, strategische stemmers of twijfelaars. Dat is in dit geval mogelijkerwijs best een deel van de verklaring, maar de richting van de afwijking vermoedt ook dat er meer systematische patronen zijn. In zetels uitgedrukt zaten de grootste verschillen bij de PVV, SP, VVD en het CDA. De PVV en SP deden het minder goed dan in de slotpeilingen, iets wat ook in 2011 al te zien was. Het CDA deed het juist beter, iets wat ook te verwachten viel op basis van historische patronen. Het verschil bij de VVD zagen we niet in 2011; zou hier misschien sprake zijn van een last-minute rally (we zagen in de Peilingwijzer voor de Tweede Kamer een stijgende lijn) of is er toch sprake van een afwijking in de peilingen?
Over het algemeen is het beeld echter best gunstig. Peilingen zijn geen perfecte voorspellers, maar dat mag je ook niet verwachten. De uitslag viel in ieder geval binnen de marges die Peil.nl, Stuk Rood Vlees (o.b.v. de Peilingwijzer) en het Gemiddelde van de peilingen bij de NOS hadden aangegeven.
Dat juist het model van Stuk Rood Vlees, dat een weging op basis van historische patronen bevatte, het goed doet, sluit aan bij de literatuur op dit vlak. Die laat zien dat prognoses op basis van een combinatie van structurele factoren én peilingen over het algemeen het beste resultaat geven.

Dus we moeten het ook in de toekomst doen met een reeks verschillende peilingen die we vervolgens moeten middelen om de tekortkomingen van die peilingen weg te werken. Je vraagt je dan af of het niet ook kan met één goede peiling.
Zoals je weet zijn likely voter weging en vertekening door non-respons problemen waar peilers overal last van hebben. Natuurlijk zou het goed zijn als peilers die problemen nog verder proberen aan te pakken (door betere steekproeven te trekken en/of door betere wegingsprocedures toe te passen). Als dat echter ongecompliceerd zou zijn (binnen de financiële kaders waarin gewerkt moet worden), dan zouden ze dat toch al lang doen, zou ik denken?
Complexiteit lijkt me niet zo’n issue. Dat kunnen de meeste peilers wel aan. Ik denk meer dat gebruikte weegmethoden onvoldoende effectief zijn. Het gaat m.i. vooral om betere weegvariabelen.
Ik denk ook dat de problemen veroorzaakt door non-respons, meestal minder groot zijn dan de problemen veroorzaakt door zelfselectie (niet loten).