Het zal trouwe lezers van ons blog zijn opgevallen dat we het afgelopen jaar met enige regelmaat stukjes hebben geplaatst uit de onderwijssociologie. Vorig jaar publiceerde RTL Nieuws in samenwerking met Jaap Dronkers een lijst van basisscholen op basis van de Cito-toets. Deze ruwe Cito-scores werden (zo goed mogelijk) gecorrigeerd voor de socio-economische samenstelling van scholen om de toegevoegde waarde van een basisschool te kunnen bepalen. Vandaag publiceert RTL Nieuws een update van de scholenlijsten, dit maal zonder directe samenwerking van Dronkers.
Ik ben een volslagen leek op dit terrein – inmiddels ben ik door mijn driejarige zoontje wel ervaringsdeskundige als het aankomt op plaatsing, maar dat terzijde… – maar het idee achter het berekenen van een toegevoegde waarde is vrij intuïtief. Hieronder mijn poging deze intuïtie samen te vatten (ik laat me uiteraard graag corrigeren in de comments) en de argumenten van voor- en tegenstanders in kaart te brengen.
Toegevoegde waarde
De veronderstelling is dat scholen verschillen op tal van kenmerken, van leerlingen- tot docentenpopulatie, van faciliteiten tot groepsgrootte. Stel, je selecteert twee identieke groepen leerlingen, bijvoorbeeld op basis van opleiding van de ouders, etniciteit, etc. De vraag is dan of de ene school ‘meer’ kan halen uit vergelijkbare groepen leerlingen dan de andere school, bijvoorbeeld omdat de ene school met kleinere groepen werkt, een andere lesmethode hanteert of meer gekwalificeerde docenten inzet. Nogmaals, ik ken de vakliteratuur uit de sociologie niet op dit punt, maar er zullen ongetwijfeld bibliotheken zijn volgeschreven over het wel of niet bestaan van deze ‘schooleffecten’.
Als je andersoortige groepen leerlingen met elkaar vergelijkt kun je die toegevoegde waarde van de school onmogelijk bepalen, omdat verschillen in allerlei vaardigheden aan het einde van de rit net zo goed het resultaat kunnen zijn geweest van verschillen in de samenstelling van de leerlingenpopulaties. In feite komt de discussie over toegevoegde waarde neer op de aloude problematiek rondom het vaststellen van causaliteit. Als schoolkenmerken de oorzaak zijn van verschillen in vaardigheden, kun je de toegevoegde waarde van een school bepalen.
Cito-scores
De uiteindelijke toegevoegde waarde voor scholen, zoals deze door Jaap Dronkers en RTL Nieuws wordt bepaald, is het resultaat van een aantal belangrijke (en controversiële) keuzes. Een absoluut pluspunt van Dronkers’ werk is dat hij volkomen transparant is over de gebruikte data en methoden. Je kunt het oneens zijn met vrijwel iedere stap die hij zet, maar het hele proces is met gemak te repliceren.
De controverse begint al bij het bepalen van de vaardigheden waarop een school meerwaarde zou moeten hebben. Dronkers en RTL gebruiken hiervoor de Cito-toets, waarvan de gemiddelde scores per school na lang bureaucratisch getrouwtrek openbaar zijn gemaakt. Om een indruk te krijgen van mogelijke problemen van het gebruik van de Cito-toets, raad ik van harte de discussie tussen Jaap Dronkers en Alderik Visser aan onder een stuk van Jaap over kwaliteitsindicatoren in het onderwijs. Zo schrijft Visser:
“Van [Cito-scores] weten wij allen, u ook, dat de gemiddelde CITO-scores van scholen, al dan niet gecorrigeerd voor leerlingpopulaties, misschien in theorie wel goede voorspellers zijn van schoolprestaties, maar dat dat in de praktijk al lang niet (meer) meer het geval is. Door het grote maatschappelijke én persoonlijke belang dat aan de CITO-score is en wordt gehecht, is de uitslag ervan niet alleen ‘gewoon’ inflationair geworden (Koretz 2008a, 2008b), maar wordt er op en rond de eindtoets basisonderwijs ook veel zachte en harde fraude gepleegd. Oefenen, zoals dat op veel ‘zwakke’ scholen gebeurt levert een mogelijke leerwinst van 8 punten op, hetgeen beduidend meer is dan uw 3 punten suggereert. De vraag is daarom gerechtvaardigd of de CITO-eindtoets basisonderwijs sowieso nog wel een goede maat is.”
Mijn indruk is dat andere ‘leeropbrengsten’ dan de Cito-scores veel minder systematisch worden verzameld en daardoor niet bruikbaar zijn voor de methode-Dronkers. Als andere indicatoren beschikbaar zouden zijn, kun je, in theorie althans, ook voor deze leeropbrengsten een toegevoegde waarde bepalen. Toch is Dronkers zelf niet zo negatief over Cito-toetsen als leeropbrengst (zie het tweede bullet point).
Leerlingenpopulatie
Maar zelfs al zouden we het eens kunnen worden over het gebruik van gemiddelde Cito-scores per school als een maat voor leeropbrengsten, dan valt er nog genoeg te twisten. Wordt er wel goed (genoeg) gecorrigeerd voor socio-economische samenstelling van de leerlingenpopulatie van scholen? Dronkers en RTL gebruiken hiervoor een maat voor de bevolkingssamenstelling van een buurt, die de leerlingenpopulatie van een school zou benaderen. René Schulenberg heeft laten zien dat met gebruik van nauwkeurigere, maar helaas niet publiek beschikbare, demografische data de resultaten best kunnen afwijken. Scholen die van RTL een bovengemiddelde score krijgen, komen in een andere categorie terecht wanneer je een betere correctie op sociale achtergrondkenmerken toepast.
{kind=link}
Dronkers geeft in een reactie op Schulenberg ruiterlijk toe dat diens maat ‘een stap vooruit is’, maar merkt terecht op dat deze data niet publiekelijk beschikbaar zijn en derhalve niet ingezet kunnen worden om in alle openbaarheid toegevoegde waardes van scholen te bepalen. Dat mag zo zijn, maar de oefening van Schulenberg laat weldegelijk zien dat een andere meting van achtergrondskenmerken bepalend kan zijn en dat daarmee de ceteris paribus-voorwaarde die ten grondslag ligt aan het bepalen van een toegevoegde toch te wensen overlaat.
Modellen
Maar zelfs al zouden we het eens kunnen worden over het gebruik van gemiddelde Cito-scores per school als een maat voor leeropbrengsten én dezelfde maat voor bevolkingssamenstelling gebruiken als RTL en Dronkers, dan nóg valt er genoeg te twisten.
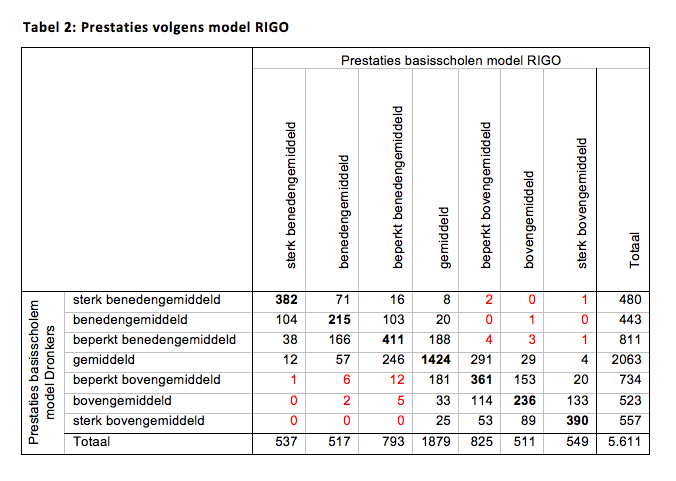
Thijs Bol schreef vorig jaar naar aanleiding van de eerste RTL-scholenlijst een methodologische kritiek, die nog steeds behoort tot één van onze meest gelezen blogs. Thijs laat zien dat een minimale verandering aan de modelspecificatie (voor de liefhebber: hij voegt kwadratische termen toe aan de regressie van Dronkers) ook leidt tot andere cijfers voor de toegevoegde waarde van scholen. Uiteraard zijn de verschillen klein, maar voor individuele scholen kan het weldegelijk een wereld van verschil maken, aldus Thijs:
{kind=link}
“Laat ik er één uit pakken als voorbeeld: basisschool De Linde uit Vroomshoop. Bij het door RTL4 gebruikte model van Dronkers haalt deze school het hoogste cijfer van alle 6 scholen in Vroomshoop: een 8,8. In mijn model haalt basisschool de Linde een 7,1, het laagste cijfer van heel Vroomshoop. Ook wordt in mijn model de top-10 door de war geschud. Zo staat basisschool Johannes Calvijn uit Urk geen 2e maar 7e. Dit soort verschillen zijn ontzettend belangrijk en beïnvloeden de keuze die ouders maken.”
De taak van wetenschappers
Het blijft een fascinerende discussie: hebben de scholenlijsten van RTL en Jaap Dronkers zelf wel een toegevoegde waarde? Wat is het effect van dergelijke lijsten op de keuzes die ouders maken en op eventuele hervormingen en activiteiten op de onderwijsvloer? Als scholenlijsten daadwerkelijk deze invloed hebben, dan rust er een gigantische verantwoordelijkheid op de schouders van wetenschappers en journalisten om betrokkenen goed te informeren over schooleffecten. Maar wat is hier ‘goed’ en wat is ‘goed genoeg?’
Thijs Bol is keihard in zijn oordeel: “Door het inbrengen van een wetenschapper, en een “wetenschappelijke” methode, wekt RTL de illusie dat scholen beoordeeld worden op hoe goed zij presteren. Totdat we goede data hebben van de sociaal-economische compositie van scholen zou mijn voorkeur uitgaan naar het publiceren van de ruwe CITO-scores. Dan is in elk geval volkomen duidelijk dat er appels met peren worden vergeleken.”
Dronkers heeft hier uitgebreid op gereageerd en is van mening dat het de taak van wetenschappers is om de ruwe Cito-scores zo goed mogelijk te corrigeren: “Ik heb daarbij de afweging gemaakt dat suboptimaal vastgestelde toegevoegde waarde beter is dan een publicatie van alleen ruwe scores.”
Dronkers heeft inmiddels aangegeven te stoppen met het maken van scholenlijsten. Vanmorgen deelde hij op Twitter alvast een plaagstootje uit aan zijn collega’s. Geven sociologen hiermee definitief het stokje over aan de journalistiek of wordt er vanuit de universiteit toch nog gehoor gegeven aan de oproep van Dronkers om ‘maatschappelijke dienstverlening’ van deze soort te verrichten? We wachten af…
RTL berekent toegevoegde waarde. Wetenschappers teruggetrokken in ivoren toren ten koste van relevantie. Onderzoeksjournalisten rukken op.
— Jaap Dronkers (@DronkersJ) July 8, 2014
– Bijna alle wetenschappelijke artikelen over effecten van scholen en onderwijsstelsels proberen met behulp van achtergrondkenmerken de toegevoegde waarde van scholen vast te stellen, om vervolgens de additionele effecten van stelsels beter te kunnen schatten. Dit recente artikel is daarvan een goed voorbeeld en is gepubliceerd in een van de beste sociologische vakbladen: http://apps.eui.eu/Personal/Dronkers/articles/SocialForces2014.pdf
– Critici klagen over het gebruik van CITO-scores als benchmark voor prestaties van leerlingen en scholen, maar dragen nauwelijks alternatieven aan. Ik doe dat wel en heb die ‘alternatieve leeropbrengsten’ gebruikt in een paper op de jongste OnderwijsResearchDagen over smalle en brede effectiviteit van basisscholen (afgeleid uit cito-score (smal) of uit succes in VO (breed)): http://apps.eui.eu/Personal/Dronkers/Lecture/brede%20toegevoegde%20waarde.pdf. Een van de interessante voorlopige uitkomsten van dit ORD paper was dat leerlingen die basisscholen hebben bezocht met een hogere smalle effectiviteit, in 3de jaar van voortgezet onderwijs een hogere positie halen. Dit effect zwakt wel af naarmate de school beter presteert. Een mogelijke verklaring van de afzwakking van dit positieve effect van een hoge smalle effectiviteit zou een excessieve testtraining kunnen zijn.
– Ik heb onlangs in een blog op stukroodvlees laten zien dat adviezen van basisscholen nog veel meer inflatoir zijn dan CITO-toetsen: http://stukroodvlees.nl/opleiding/zijn-schooladviezen-aan-inflatie-onderhevig/. CITO-toesten zijn dus niet zo’n slechte benchmark.
– De RTL heeft indicatoren die Rene Schulenburg suggereerde en die publiek beschikbaar zijn gebruikt in hun berekening van toegevoegde waarde. Ook op dit punt is vooruitgang.
Het blijft een belangrijke discussie.
t.a.v. het eerste punt van Dronkers, over de toegevoegde waarde van scholen: Het maakt nogal uit of je de toegevoegde waarde gebruikt in analyses over gemiddelden van populaties (bijv: hoe presteren RK-scholen tov openbare scholen in het algemeen), of dat je die toegevoegde waarde gebruikt om individuele scholen te ranken.
RTL gebruikt de methode voor het laatste. En daar gaat het fout. De achterliggende statistiek werkt om gemiddelden te verklaren/beschrijven, maar niet individuele gevallen. En de ranking van individuele scholen tov andere individuele scholen in de omgeving is daar heel gevoelig voor.
Wetenschappers kunnen niet hun schouders ophalen voor onjuist gebruik van dit soort cijfers, omdat het wel degelijk maatschappelijke gevolgen kan hebben.
Ik ben met Tom van der Meer eens dat er een verschil zit tussen uitspraken over populaties (de RK-scholen) of individuele scholen. Maar dat verschil moet niet overdreven worden, want 1. De CITO cijfers zijn een gemiddelde over 3 jaar, en dus geen eenmalige gebeurtenis. 2. De cito cijfers zijn al een aggregaat over alle leerlingen van groep 8, dus een deel van de ruis is door de aggregatie eruit. Het gaat dus niet om privé personen met een eigen privacy, maar om belangrijke instituties. 3. Als wel afzonderlijke politieke partijen vergeleken worden (” deze week D’66 twee zetels omhoog bij de Hond”), dan zie ik niet in waarom dat bij nog belangrijker instituties als scholen niet mag.
De onzekerheid zit wat mij betreft niet in het gebruik van de CITO-cijfers, maar in de statistiek achter het ijkpunt waar toegevoegde waarde op berekend is. Die statistiek is niet perfect, en heeft dus een foutmarge. Dat leidt precies tot de problemen die onder punt 3 worden genoemd: de ranking/verschillen/veranderingen moeten wel hard gemaakt kunnen worden. Op dit blog hebben we ook al heel vaak aangegeven dat daar in het geval van zetelpeilingen serieuze problemen mee bestaan.
Dat geldt in zekere zin ook hier. Toegevoegde waarde gebaseerd op statistiek impliceert foutmarges bij een model dat niet perfect voorspelt. Hoewel het hier niet gaat om meetonzekerheid door het gebruik steekproeven (zoals bij zetelpeilingen) omdat dit de populatie is. Het gaat hier om meetonzekerheid door een imperfect model dat de ijkpunten bepaalt.
Dit is wat mij betreft een probleem omdat de RTL-lijst primair wordt gebruikt voor vergelijking van individuele gevallen.
Goed om te zien dat de RTL-lijst nu betere data gebruikt. Tegelijkertijd kun je je afvragen of alleen inkomen en opleiding als extra variabelen voldoende is om te corrigeren voor de sociaal-economische kenmerken van de leerlingenpopulatie. Er zijn nog wel meer gegevens bij het CBS beschikbaar die van belang kunnen zijn (werkloosheid, bijstand, etniciteit). Zeker nu afkomst van de leerlingen zelf niet meer meegenomen kan worden zou dat verstandig zijn geweest.
Punt – dat Tom vd Meer ook al maakt – blijft echter dat je hiermee geen ranglijst kunt maken. Je weet niet waar je naar zit te kijken als je het residu van de regressie als toegevoegde waarde van de school ziet: is dat de modelonzekerheid of is dat de toegevoegde waarde. De modelonzekerheid bestaat bijvoorbeeld uit de data van de bewoners van de postcodes die gebruikt is. Het is beter dan niets, maar postcodegebieden zijn zo groot (gemiddeld 4000 inwoners) dat je bijna zeker weet dat het gemiddelde van zo’n postcodegebied niet exact het gemiddelde van de leerlingen weergeeft. Dat gaat onherroepelijk tot foutmarges in het residu leiden. En dat kan verschillen van stad tot stad. In een gesegregeerde stad als Den Haag kun je dit misschien wel beter doen (want meer homogene postcodes) dan in een gemengde stad als Almere. Een ranglijst is echt een stap te ver.
Überhaupt is het gebruik maken van postcodes niet verantwoord. In het basisonderwijs is de segregatie op schoolniveau groter dan de segregatie op wijkniveau. Dit speelt, vanzelfsprekend, met name in steden. Ook precies die plekken waar de volgorde in lijsten van invloed op keuzegedrag kan zijn. Wie met verstand van onderwijs naar deze lijsten kijkt, ziet meteen welke schooltypen hiervan profiteren.
Postcodes van leerlingen (niet van scholen) is zeker niet ideaal om hun ouderlijk milieu te meten. Beter zou zijn de individuele oudergegevens te gebruiken, die wel beschikbaar zijn maar door DUO om privacy niet beschikbaar gesteld mogen worden. Maar het gebruik van de postcodes en de daaraan gehangen indicatoren, samen met de gewichten van de leerlingen (=laag ouderlijk milieu) is een betere meting van de variatie in de sociaal-compositie van basisscholen dan alleen maar de gewichten van de leerlingen, zoals gebeurd door de inspectie (http://stukroodvlees.nl/opleiding/de-onderwijsinspectie-is-inderdaad-te-soft/). De verklaarde variantie in CITO-scores van scholen is beduidend als, naast de leerling-gewichten, ook indicatoren gekoppeld aan postcodes worden gebruikt.
Het is zeker geen perfect meetmodel, dat ben ik met Tom van der Meer eens.
– Maar ten eerste bestaat er geen perfect meetmodel, het is op zijn best een meetmodel met een redelijke waarschijnlijkheid. Ook al zouden wij het individuele aanvangsniveaus van de leerlingen in groep 1 of 3, de opleidings- en beroepsniveaus van hun ouders en hun individuele CITO-toets weten en multilevel-analyse kunnen toepassen, dan nog zullen wij vinden dat zowel op het niveau van de leerling als op het niveau van de school een deel van de variantie in CITO-scores niet met dit betere meetmodel verklaard kan worden. Deze onverklaarde variantie is niet het gevolg van een een onvoldoende meetmodel, maar is inherent aan samenlevingen van mensen en van andere dieren. Jencks noemde die onverklaarbare variantie “geluk” of “pech” (Jencks, C. et al. 1979. “Who Gets Ahead? The Determinants of Economic Success in America.” New York: Basic Books). Kortom, ook bij meetmodellen moeten wij toeval kunnen accepteren aan een vast onderdeel van dat model en niet alleen zien als een fout.
– Ten tweede: als astronomen (een tak van wetenschap die het, net als de sociologie, bijna uitsluitend met veldwaarnemingen met ruis moet doen) gewacht zouden hebben totdat zij een perfect meetmodel zouden hebben, zou de zon nog steeds om de aarde draaien.
Nu je niet meer werkt aan de scholenlijsten, Jaap, zie ik graag een ranking van de meest leefbare planeten in de meest vijandige sterrenstelsel tegemoet 😉
Het gaat natuurlijk om het punt van Tom: individuele voorspellingen doen op basis van een algemeen model is geen goed idee. Zeker niet omdat de uitwerking van de schoollijsten lokaal is–het zal iedereen worst weten wat de beste school is, mensen willen weten hoe goed de school in hun gemeente is.
Niemand stelt dat je geen voorspellingen mag doen op basis van meetmodellen, we doen dat allemaal in onze artikelen, al dan niet impliciet.
Het belangrijke punt is dat dit niet gepubliceerd is in een vaktijdschrift waar collega’s weten welke onzekerheid er in voorspellingen is ingebouwd. Dit is gepubliceerd op een website, met als doel mensen (voornamelijk statistische leken) te informeren. De resultaten zijn in grote mate onzeker en afhankelijk van het meetmodel; maar zo wordt het absoluut niet gepresenteerd. Waarom op deze manier presenteren?
Alle peilingen die stellen exact het aantal zetels te kunnen voorspellen liegen. Schoolcijfers geven achter de komma is op exact dezelfde manier het misbruiken van statistiek. Ik zou daar als wetenschapper nooit aan meewerken.
Waarom niet een onderscheid maken tussen drie groepen? Waarom niet aangeven welke scholen grensgevallen zijn? Volgens mij verwacht niemand een perfect meetmodel Jaap, we verwachten een rapportage van de resultaten die aansluit bij de onzekerheid die gepaard gaat met het model.
Astronomen die op basis van hun eerste meetmodellen een exacte voorspelling deden van de snelheid waarmee de aarde om de zon draait maakten dezelfde fout als er nu gemaakt wordt met de schoollijsten.
Gelukkig maakte Galileo wel die berekening van de snelheid waarmee de aarde om de zon draaide. En hetzelfde deed hij voor alle toen bekende planeten en de maan. Op grond daarvan voorspelde hij hun posities aan de hemel en vergeleek die met de metingen van die posities door Brahe. Zijn voorspellingen waren nauwkeuriger dan die welke volgden uit het geocentrische systeem van Ptolemeus (zon, maan en planeten draaien om vaststaande aarde). Perfect waren zijn voorspellingen echter nog niet, omdat Galileo (maar ook zijn tijdgenoten) veronderstelde dat aarde en planeten in cirkels om de zon draaiden. Newton verving bijna een eeuw later deze cirkels door ellipsen, en kon pas zo de posities van de planeten perfect voorspellen. Maar ondanks het imperfecte meetmodel van Galileo waren zijn berekeningen een grote stap voorwaarts in de overgang naar een heliocentrisch systeem. Wij moeten dus blij zijn dat hij niet heeft gewacht tot er een perfect meetmodel zou zijn.
Er is nogal een verschil tussen planetaire bewegingen becijferen (die niet worden beinvloed door menselijk gedrag) en imperfecte ranglijsten presenteren (waar mensen zich wel degelijk op baseren).
Mijn probleem zit niet in je presentatie van uitkomsten van een model. Mijn probleem zit in het negeren van de forse onzekerheid die gepaard gaat met dit model, en waarvan je gegeven de verklaringskracht en de alternatieve modellen op de hoogte bent.
Het verwijt over de ivoren toren komt als een boemerang terug als je dit model verdedigt via Galileo’s meetmodel.
Deze ranglijst is maatschappelijk relevant, en juist daarom moet je niet preciezer (willen) zijn dan mogelijk is met de beperkte gegevens die je hebt.
Je doet maw precies wat je zetelpeilers verwijt.
Kepler, Jaap. Zijn derde bewegingswet, geloof ik, ook ‘uitgevonden’ door het computerprogramma BACON van Herbert A. Simon.
http://articles.latimes.com/1992-04-24/local/me-933_1_los-angeles-times
De Grieken waren het met elkaar niet eens over een heliocentrisch wereldbeeld, zoals dat van Aristarchus
http://en.wikipedia.org/wiki/Aristarchus_of_Samos
die ook de afstand tot de Maan en de Zon kon berekenen, en in beginsel dus ook de snelheid van de Aarde in zijn baan om de zon.
Leuker dan ranglijstjes.
Voor de onderwijsexperts: bestaat er onderzoek naar schoolkeuze van ouders en de rol van ranglijsten (of andere vormen van informatie over ‘schoolkwaliteit’) op hun keuze?
– onderzoek naar schoolkeuze van ouders is een klassiek onderwerp vanaf de jaren ’70. Het is nu een hele berg literatuur.
– de eerste studie naar de rol van ranglijsten op keuze van ouders is van mijn hand: “Veranderden leerlingaantallen in het voortgezet onderwijs in het schooljaar 1998-1999 door de publicatie van inspectiegegevens en de berekening van het schoolcijfer door Trouw in oktober 1997? Een nadere analyse.” Tijdschrift voor Onderwijsresearch 24:63-66 (1999). Vier mooie recente publicaties zijn: Luyten, H. & De Wolf, I.F. (2011) Changes in student populations and Average Test Scores of Dutch Primary Schools. School Effectiveness & School Improvement, 22 (4), 439-460; Luginbuhl, R, Webbink, D. & De Wolf, I.F. (2009) Do School Inspections Improve Primary School Performance? Educational Evaluation and Policy Analysis, 31(3), 221-237; P. Koning & K. van der Wiel, Ranking the Schools: How Quality Information Affects School Choice in The Netherlands (2013), Journal of European Economic Association, Vol. 11 (2), p. 466-493: P. Koning & K. van der Wiel, School Responsiveness to Quality Reports: An Empirical Analysis of Secondary Education in The Netherlands (2012), De Economist, Vol. 160 (4), p. 339-355.
– Ik vergat nog te vermelden dat Galileo zijn bevindingen niet in het Latijn publiceerde (vakgenoten), maar in het Italiaans (het beroemde “Discorsi e Dimostrazioni Matematiche, intorno a due nuove science”), dus voor leken. Brecht geeft in zijn toneelstuk “Leben des Galilei” een goed beeld van de discussie over het politieke en ideologische belang om zijn verontrustende inzichten verborgen te houden voor het lekenpubliek.
Waarde heren,
Het valt mij op dat in deze toch alleszins belangwekkende discussie inhoudelijke en normatieve commentaren soms op een wonderlijke wijze door elkaar heen lopen. Enerzijds is er inhoudelijke kritiek, maar anderzijds lijkt men zich per se druk te maken over de wijsheid van het besluit de gecorrigeerde cijfers te publiceren. Op zichzelf is de inhoudelijke kritiek niet noodzakelijkerwijs onterecht, maar de kwestie die hier door niemand serieus wordt aangesneden (behalve door Armin in zijn oorspronkelijke post) is, is de tweede. Hoe wijs is de publicatie van maatschappelijk relevante resultaten die gebaseerd zijn op onvolmaakte gegevens?
Hier wordt vanuit verschillende beginaannames geredeneerd, hetgeen voorkomt dat deze discussie tot een bevredigend einde kan worden gebracht. Zowel Tom als Thijs vinden de publicatie van rangordeningen op basis van imperfecte modellen te bekritiseren, en stellen om die reden per definitie tegen de publicatie van die cijfers te zijn. Jaap beaamt dat de methodiek weliswaar niet volmaakt is, maar stelt dat de gecorrigeerde cijfers desondanks een belangrijke verbetering zijn ten opzichte van de presentatie van de ruwe cijfers. Het gaat Jaap dus om de verbetering; de ranglijsten zelf staan niet ter discussie.
Ik deel Jaaps mening en aanpak. Iemand vraagt hierboven (terecht) waarom ervoor gekozen is om ranglijsten te publiceren. Uwe edelen beseft neem ik aan wel dat er ook op basis van de ruwe scores ranglijsten zouden worden gemaakt? Je kunt debatteren over de interpretatie van het residu (lijkt me nuttig), en over de volledigheid van de modellen (lijkt me ook nuttig), en je kunt zelfs debatteren over de zin en onzin van ranglijsten (wellicht ook nuttig). Het gegeven dat de gecontroleerde scores /beter/ voor instroom controleren dan de niet-gecontroleerde scores lijkt mij echter evident. Zoals ik het zie, is dat in wezen de enige claim die Jaap maakt.
Hoe wijs is het met onvolmaakte gegevens en onvolmaakte methoden data met real life consequences te publiceren? Welnu, dat /hoeft/ geen probleem te zijn. Onvolmaakte gegevens en methoden zijn ook in onze papers bepaald niet zeldzaam. De afwegingen daarover kunnen en mogen door eenieder anders worden gemaakt, maar het lijkt mij getuigen van een zekere epistemologische hoogmoed te suggereren dat sociale wetenschappen meer zouden kunnen doen dan met de best mogelijke methoden de beste beschikbare gegevens te analyseren om tot zo verstandig mogelijke antwoorden op onderzoeksvragen te komen. Het is de taak en de verantwoordelijkheid van de individuele wetenschapper om de afweging tot het publiceren van om het even welke onderzoeksbevindingen op een integere en prudente wijze te maken. Transparantie over de beslissingen en openheid over data- en modelbeperkingen zijn daarom van het allerhoogste belang: dan zijn de beperkingen duidelijk en valt er over de besluiten te discussiëren. Ik interpreteer het levendige debat dat naar aanleiding van de publicaties is ontstaan als een bewijs dat de schoolcijferlijsten op dit punt erg geslaagd zijn.
Ik kan mij in het kader van de transparantie niet inhouden een tweetal hierboven aangedragen argumenten van nader commentaar te voorzien. Thijs vindt het problematisch dat de zaak niet aan het peer review proces heeft blootgestaan. Maar iets hoeft niet noodzakelijkerwijs in een journal te staan om peer reviewed te zijn. De constructie van het model is bepaald niet over één nacht ijs gegaan, en het is niet zo dat Jaap heeft nagelaten om deze werkwijze aan zijn peers voor te leggen. Wees gerust: wij hebben in Maastricht de voors en tegens van de verschillende meetmodellen uitgebreid intern bediscussieerd. Uiteindelijk zijn wij na ampel beraad gezamenlijk tot de conclusie gekomen dat het maatschappelijk belang het meest gediend zou zijn met de publicatie van de gecorrigeerde cijfers. Immers, die rangordeningen worden toch wel gemaakt. Maar om te voorkomen dat mensen de rangordening zouden verabsoluteren, vond Jaap het essentieel de methodiek transparant te maken, en hebben wij ernaar gestreefd nergens claims neer te leggen die het model niet kan waarmaken. In overeenstemming met dat streven hebben wij er zo goed mogelijk zorg voor gedragen de gecorrigeerde cijfers te presenteren als een controle voor leerlingencompositie, en hebben wij overal waar dat mogelijk is nuances aangebracht en uitgelegd dat de correctie niet volmaakt is. Nergens is de indruk gewekt dat de methode het laatste antwoord zou zijn. Wel dat het het beste antwoord mogelijk is, gegeven 1) de wens voor instroom te controleren en 2) de gebrekkigheid van de gegevens.
Ten tweede wordt gesuggereerd dat er allerlei moeilijke statistiek zou worden uitgestort over weerloze, onwetenschappelijke leken. Maar wij hebben ons uiterste best gedaan onze toelichting zo te schrijven, dat zij ook door mensen met weinig statistische kennis te lezen en te begrijpen zou zijn. Daarnaast besteedt Jaap bijzonder veel tijd aan nazorg: ouders, leerlingen, schooldirecteuren en leraren die na het lezen van de toelichting nog steeds met serieuze vragen om verheldering zitten (of peers die kritiek hebben op de methode) krijgen binnen een dag een inhoudelijk en genuanceerd antwoord. Dat kost vreselijk veel tijd, maar is de enige manier om zeker te weten dat mensen die met kwesties zitten, zo goed en genuanceerd mogelijk van advies worden voorzien.
Ik geloof dat niemand twijfelt aan het maatschappelijk belang dat de lijsten beogen te dienen, en het blijft een interessante vraag hoe wij als wetenschappers zo prudent mogelijk met de ons ter beschikking staande gegevens om moeten gaan. Dat is immers onze dagelijkse praktijk. Daarom valt mij op dat geen van de jonge wetenschappers die zich in het debat mengen met een concreet voorstel tot modelverbetering voor de dag komt. Dat is jammer, want zo blijft de discussie richtingloos. Kritiek op de methodiek kan uiterst vruchtbaar zijn, en heeft in het verleden steevast geleid tot een verbetering van de modellen. Ik zou het dan ook aanmoedigen als mensen hun methodologische kritiek vergezeld zouden doen gaan van concrete aanwijzingen over hoe het volgens hen beter zou kunnen. Botweg stellen dat je je als “wetenschapper” niet zou inlaten met een exercitie die gebruik maakt van onvolmaakte gegevens is wel erg gemakkelijk. Beken maar eens kleur, en laat maar eens concreet zien wanneer je dan wel tevreden zou zijn. Zo hoort een serieuze discussie te gaan, nietwaar?
Vriendelijke groeten,
Mark
Hoi Mark,
Dank voor je uitgebreide reactie. De kern van de kritiek van Thijs, Tom en René (en eentje die ik deel) is dat je niet moet doen alsof het model perfect is. Natuurlijk bestaan er geen perfecte modellen, maar door op basis van een regressiemodel individuele scores voor scholen uit de residuen te gebruiken als rapportcijfers doe je wel alsof het een perfect model is. Het alternatief is al meerdere keren door Thijs e.a. aangedragen, namelijk dat je die residuen (ook al besluit je die als rapportcijfers te presenteren) met een mate van onzekerheid zou kunnen presenteren.
Zolang het meetmodel niet perfect is (en dat blijft zo) moet je in de presentatie en interpretatie van resultaten ook niet doen alsof dat wel zo is. Dit is de kern van de geuite kritiek (nog los van de wenselijkheid om leeropbrengsten te kwantificeren en het gebruik van welke concrete leeropbrengsten hiervoor) en ik hoop dat Jaap zou kunnen aangeven wat er op tegen zou zijn om rapportcijfers met een marge te publiceren zodat mensen niet denken dat een school met een 7,1 dus meer toegevoegde waarde heeft dan een school met een 7,0.
Beste Mark,
Ranglijsten worden sowieso gemaakt, op basis van ruwe scores of op basis van gecorrigeerde scores.
Bij publicatie van ruwe scores kan je uitleggen wat het probleem is (verschil in instroom). Dat is simpel uit te leggen.
Bij publicatie van gecorrigeerde scores ontstaat een dubbel probleem. Enerzijds zijn de scores (residuen) itt de ruwe scores niet langer zonder foutmarge. Anderzijds is het model imperfect. Betekent dat dat je dit niet mag publiceren? Natuurlijk mag dat. Maar het is onwenselijk om de onzekerheid die je als onderzoeker zelf introduceert vervolgens te negeren. Op het macro-niveau maakt die ruis misschien niet uit, op het micro-niveau doet het dat wel. De schijnprecisie leidt tot een ranking die zonder veel aanpassingen aan het model anders uit kan pakken. Dat heeft voor scholen, ouders en kinderen wel degelijk gevolgen.
Het is prachtig dat er een toelichting is, en dat er nazorg is. Maar dat zou al gereflecteerd moeten zijn in de cijfers en ranking zelf. Juist door de suggestie dat dit model corrigeert voor instroom, nemen lezers het serieuzer dan gebeurt. Hoeveel reacties jullie ook krijgen, er zal een veelvoud aan lezers bestaan die niet verder kijkt dan de ranking.
Ik snap niet goed waarom je stelt dat er geen alternatieven worden geboden. Die zijn al genoemd. Denk aan foutmarges, minder precieze afrondingen, of clustering (groepen onderscheiden die duidelijk afwijken).
Voor alle duidelijkheid: niemand hier twijfelt volgens mij aan de oprechtheid en goede intenties van de onderzoekers.
Hoi Armin,
Hartelijk dank voor je reactie. Ik begrijp de kern van de kritiek wel, maar geloof dat ik het oneens ben met de interpretatie dat er ergens door Jaap gesuggereerd wordt dat de modellen perfect zouden zijn. Integendeel, zou ik bijna zeggen: de toelichting bij de methode laat zich toch vooral lezen als een poging met onvolmaakte gegevens toch een stap vooruit te zetten. Ook in zijn reacties op alle posts en in de mailwisselingen met mensen die vragen stellen is Jaap de eerste om aan te geven waar de schoen wringt. Zoals het een wetenschapper betaamd, ben ik geneigd er aan toe te voegen.
De verwarring ontstaat doordat Jaap de maatschappelijke behoefte aan vergelijkende informatie over de kwaliteit van scholen als gegeven neemt, en van daaruit is gaan redeneren. Dan kom je al snel uit op vragen over hoe je die kwaliteitsvergelijking het beste inzichtelijk kunt maken. Ranglijsten zijn daartoe een veelgebruikt en mogelijkerwijs uiterst informatief presentatiemiddel, ondanks hun intrinsieke beperkingen. Ik weet niet of de presentatie van rangordeningen nu noodzakelijkerwijs suggereren dat het onderliggende model zonder fouten zou zijn.
Wie er eerst voor kiest ranglijsten te presenteren, kan zich daarna druk gaan maken over hoe je dat dan /zo goed mogelijk/ doet. Dan volgt de vraag over de noodzaak tot controle voor de leerlingenpopulatie, en als je eenmaal besloten hebt dat het nuttig is om dat te doen, kun je je afvragen hoe dat dan het beste kan. Het gebruik van de value added benadering zoals Eriks Hanushek die gebruikt om lerareneffecten te isoleren is in beginsel wat mij betreft zonder meer een verdedigbare keuze. Over de kennelijk suggestieve krachten van de term “toegevoegde waarde” valt best te twisten, maar dit is toch heus de benaming die in de literatuur voor dit soort interpretaties het meest gangbaar is. Ik heb daar op zich geen problemen mee, zeker niet als de nodige voorbehouden rondom interpretatie gemaakt worden. Ik vind dat Jaap die in zijn toelichting en zijn communicatie meer dan uitputtend maakt.
Dat wil niet zeggen dat die aanpak de enige juiste is, en Jaap is zoals ik hem ken ook de eerste om terechte commentaren concreet om te werken tot verbeteringen van het model. Het presenteren van onzekerheden rondom rapportcijfers zou een goede verbetering van de presentatie kunnen zijn. Moet je inderdaad serieus over nadenken. Modellen zijn altijd een gevolg van voortschrijdend inzicht, en het kan zijn dat mensen op een /nog/ verstandiger manier een school voor hun kinderen kiezen als je de onzekerheid van het model verdisconteerd. Dat gezegd hebbende zal iedere modellering op enige wijze te bediscussiëren keuzes met zich meebrengen, en moet je over dit soort dingen blijven praten. In de tussentijd vind ik dat het betere nooit de vijand van het goede mag zijn.
Met vriendelijke groet,
Mark
Snelle reactie: De ranglijst suggereert dat een 7,6 aantoonbaar beter is dan een 7,5 en die weer beter zijn dan een 7,4. Waar ligt de grens? Eerdere posts hebben al aangegeven dat een kleine wijziging kan leiden tot een omkering van de ranking van beste vs slechtste school in dorpen en stadsdelen.
Dat die kleine verschillen een artefact kunnen zijn van de modelspecificatie (gegeven verre van perfecte R-kwadraat) is simpelweg belangrijk. De ranking heeft gevolgen voor de reputatie van een school. Dat is prima, zolang het geen statistisch artefact is.
Beste Tom,
Ik ontken dat belang geenszins, en ik vind het ook goed dat jullie dit soort kanttekeningen plaatsen. Dat kan de methodiek vooruit helpen en op de langere termijn de modellen verbeteren, hetgeen uiteindelijk leidt tot een verbetering van de wijze waarop mensen scholen kiezen. En daar gaat het uiteindelijk allemaal om.
Ik vond de analyse van Thijs mooi, maar niet per se overtuigend bewijs dat de methodiek nu zo ontzettend wiebelig is: daarvoor zijn de verschuivingen in de rangorde wat mij betreft over het algemeen te marginaal. Hoewel ze belangrijk zijn, moet het belang van dergelijke kleine verschuivingen volgens mij ook weer niet overdreven worden: ik vermoed dat veel ouders volstrekt indifferent zijn als ze moeten kiezen tussen een school die op de schoolcijferlijst.nl een 7,4 scoort en een school die een 7,3 scoort.
Maar goed, ik wil de zaak niet bagatelliseren. Ik vind absoluut dat je zou moeten proberen te komen tot een robuustere schatting of een presentatiewijze die (nog) minder gevoelig is voor modelspecificaties, als dat mogelijk is. In het vaststellen van de logica achter de rangorde (of zo je wilt: het bepalen van de grens) ligt dan inderdaad de grootste uitdaging. Daar moeten keuzes gemaakt worden, en die keuzes hebben altijd consequenties voor scholen. Wellicht is het presenteren van een meetonzekerheid inderdaad een goede stap vooruit. Maar weet: hoe je die grenzen ook trekt, er zullen altijd scholen zijn die net onder de grens terechtkomen, en die om die reden die grens problematisch vinden. Dat mag nooit een reden zijn om geen grenzen te trekken.
Ik vind, en dat was de reden om mij in deze discussie te mengen, dat wij niet moeten doen alsof terechte kritiek op een wetenschappelijke methode die methode per se invalideert. Ook denk ik dat het erg onverstandig is de suggestie te wekken dat er zo iets is als het volmaakte model, of de perfecte gegevens. Hoe je dit ook modelleert: het is allemaal een kwestie van gradaties. Een wetenschapper kan wat mij betreft weinig anders dan een zo prudent mogelijke keuzes maken, open zijn over zijn of haar methodologische afwegingen, en bereid zijn in het licht van betere data of overtuigender methoden de keuzes aan te passen. Ik interpreteer Jaaps schoolcijferlijsten als een product van die filosofie
Vriendelijke groet,
Mark
Over civiele effecten van dergelijke ranglijstjes gesproken: denk eens aan de PISA-lijstjes waar individuele landen worden gerangordend op basis van een toets (lezen, of wiskunde, of natuurkunde), afgenomen aan een niet nader toegelichte steekproef.
En wat daar dan de politiek-maatschappelijke effecten van zijn.
Op de gebruikte methodiek kun je m.i. precies dezelfde kritiek oefenen als hier naar voren wordt gebracht. Daarbij zijn de verklarende factoren per land ook zeer verschillend: ligt een lagere score voor de VS t.o.v. Nederland aan slechter onderwijs, meer armoede, een heterogenere populatie? Maar de zwarte piet komt altijd weer op school terecht.
Perfecte modellen bestaan natuurlijk iet. Op zichzelf is dit ook een heel aardige manier – ondanks alle mitsen en maren – om met de gebrekkige data die er is een inschatting te maken of een school het beter doet dan verwacht (of juist niet).
Maar ik vraag me nog altijd wat af. De verschillende modellen hebben nu een verklaarde variante tussen grofweg 30 en 50 procent. Het onverklaarde deel ligt dus tussen de 50 en 70 procent. Dat bestaat uit toegevoegde waarde, uit dataproblemen, uit modelonzekerheid etc.. Is er al eens onderzoek gedaan hoe groot het deel is van de toegevoegde waarde dat je daarin ongeveer mag verwachten?
– Een aantal keren (ik dacht in 1998 en 1999) hebben Trouw en ik de schoolcijfers in 5 groepen ingedeeld: ++, +, 0, -, – – (op basis van quintielen). Wij kregen toen veel klagende scholen die bij de onderste 19% of 39% scoorden. Zij voelden zich onheus en oneerlijk bejegend dat zij net onder de grens vielen, terwijl een school net in de buurt (de lokale context) net boven de grens uitkwam en dus in een betere groep zat. Dat klagen heeft een grote rol gespeeld bij het besluit van Trouw en mij om uiteindelijk weer gewoon schoolcijfers te gebruiken en geen vijf groepen. Het gebruik van groepen creëert nieuwe problemen rond de grenzen van de groepen.
– Een andere mogelijkheid voor de RTL cito publicatie zou zijn gebruik te maken van de drie jaren waarover de RTL middelt. Je zou per school de standaard deviatie van de toegevoegde waarde van die drie afzonderlijke jaren kunnen gebruiken als indicator van de meetfout. Een specifieke school met een over de drie jaar gemiddelde toegevoegde waarde 0.9 en een meetfout van 0.1 krijgt dan een gepubliceerde toegevoegde waarde van 0.8 tot 1.0. Een bezwaar is wel dat de meetfout voor elke school anders zal zijn: bij heftig fluctuerende scholen groter dan bij stabiele scholen. Dit lijkt mij allemaal moeilijk uit te leggen aan een breder publiek. Bovendien zal dat geen enkele ouder weerhouden te concluderen dat onze voorbeeld school een gemiddelde toegevoegde waarde heeft van 0.9.
– Vorig jaar bij de Volkskrant ben ik begonnen het cijfer van het jaar daarvoor naast het nieuwste cijfer af te drukken. Als ik dit jaar opnieuw schoolcijfers in de VK gepubliceerd zou hebben, dan zou ik de cijfers van de twee vorige jaren meegeven hebben. Dat geeft de lezer(es) een indruk van de variatie. Dat zou de RTL kunnen gaan doen, nu zij voor de tweede keer CITO cijfers publiceert.